~今天要分享的是「決策樹實作」~
對於決策樹有了基本觀念後,我們來看看要怎麼使用python程式碼來分析吧~
決策樹分析模型在sklearn套件底下:from sklearn import tree
#使用在分類問題tree.DecisionTreeClassifier()
#使用在回歸問題tree.DecisionTreeRegressor()
[程式碼實作]
迴歸問題:使用sklearn的資料集”boston”進行分析
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
boston_data=pd.DataFrame(boston['data'],columns=boston['feature_names'])
print("Data:",boston_data.head())
print("===============================")
boston_target=pd.DataFrame(boston['target'],columns=['target'])
print("Target:",boston_target.head())
print("===============================")
X=boston_data[["CRIM",'ZN',"INDUS","CHAS","NOX","RM","AGE","DIS","RAD","TAX","PTRATIO","B","LSTAT"]]
y=boston_target['target']
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
from sklearn import tree
DTR=tree.DecisionTreeRegressor()
DTR.fit(X_train,y_train)
print('特徵重要程度:',DTR.feature_importances_)
print("模型解釋力:",DTR.score(X_test,y_test))
from sklearn.metrics import mean_squared_error
from math import sqrt
DTR_pred =DTR.predict(X_test)
rmse = sqrt(mean_squared_error(y_test, DTR_pred))
print("rmse: %.3f" % rmse)
print("依變數平均值:",boston_target['target'].mean())
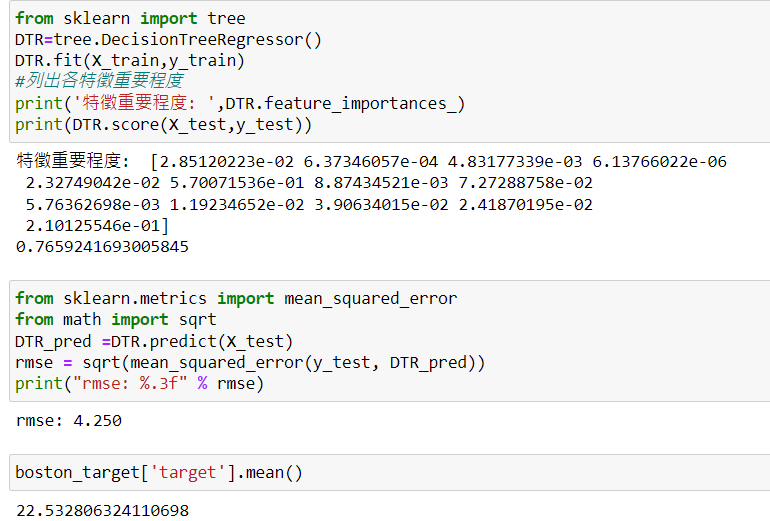
由結果可以得知,自變數X對目標值依變數Y的特徵重要程度分別是:"CRIM"(約0.029), 'ZN'(約0.0006), "INDUS"(約0.005), "CHAS"(約0.000006), "NOX"(約0.023), "RM"(約0.570), "AGE"(約0.009), "DIS"(約0.073), "RAD"(約0.006), "TAX"(約0.012), "PTRATIO"(約0.039), "B"(約0.024), "LSTAT"(約0.210),其中' RM '為分類能力最好的特徵。
另外分析結果也指出,此模型的解釋力約有0.77,且目標變數裡的數據平均值約為22.53,模型誤差只有約4.25,所以是還不錯的模型。
分類問題:使用sklearn的資料集”iris”進行分析
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_data = pd.DataFrame(iris['data'],columns=iris['feature_names'])
print("Data:",iris_data.head())
print("===============================")
iris_target=pd.DataFrame(iris['target'],columns=['target'])
print("Target:",iris_target.head())
print("===============================")
X=iris_data[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']]
y=iris_target['target']
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
from sklearn import tree
DTC=tree.DecisionTreeClassifier()
DTC.fit(X_train,y_train)
print('特徵重要程度:',DTC.feature_importances_)
print("===============================")
from sklearn.metrics import classification_report,confusion_matrix
DTC_pred= DTC.predict(X_test)
print("混淆矩陣:",confusion_matrix(y_test,DTC_pred))
print("======================================================\n")
print("模型驗證指標:",classification_report(y_test,DTC_pred))
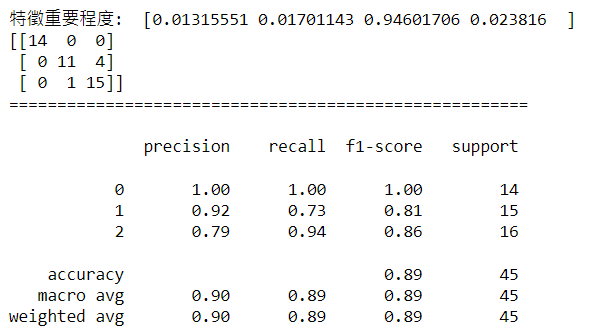
由結果可以得知,自變數X對目標值依變數Y的特徵重要程度分別是:'sepal length (cm)'(約0.013), 'sepal width (cm)'(約0.017), 'petal length (cm)'(約0.946), 'petal width (cm)'(約0.024),其中' petal length (cm) '為分類能力最好的特徵。
另外分析結果也指出,測試資料中有四筆原本分類為第2類的樣本被模型預測成第1類,以及一筆原本分類為第1類的樣本被模型預測成第2類,因此出現了一點誤差,但整體正確率高達0.89,所以是一個蠻優秀的模型。


 iThome鐵人賽
iThome鐵人賽